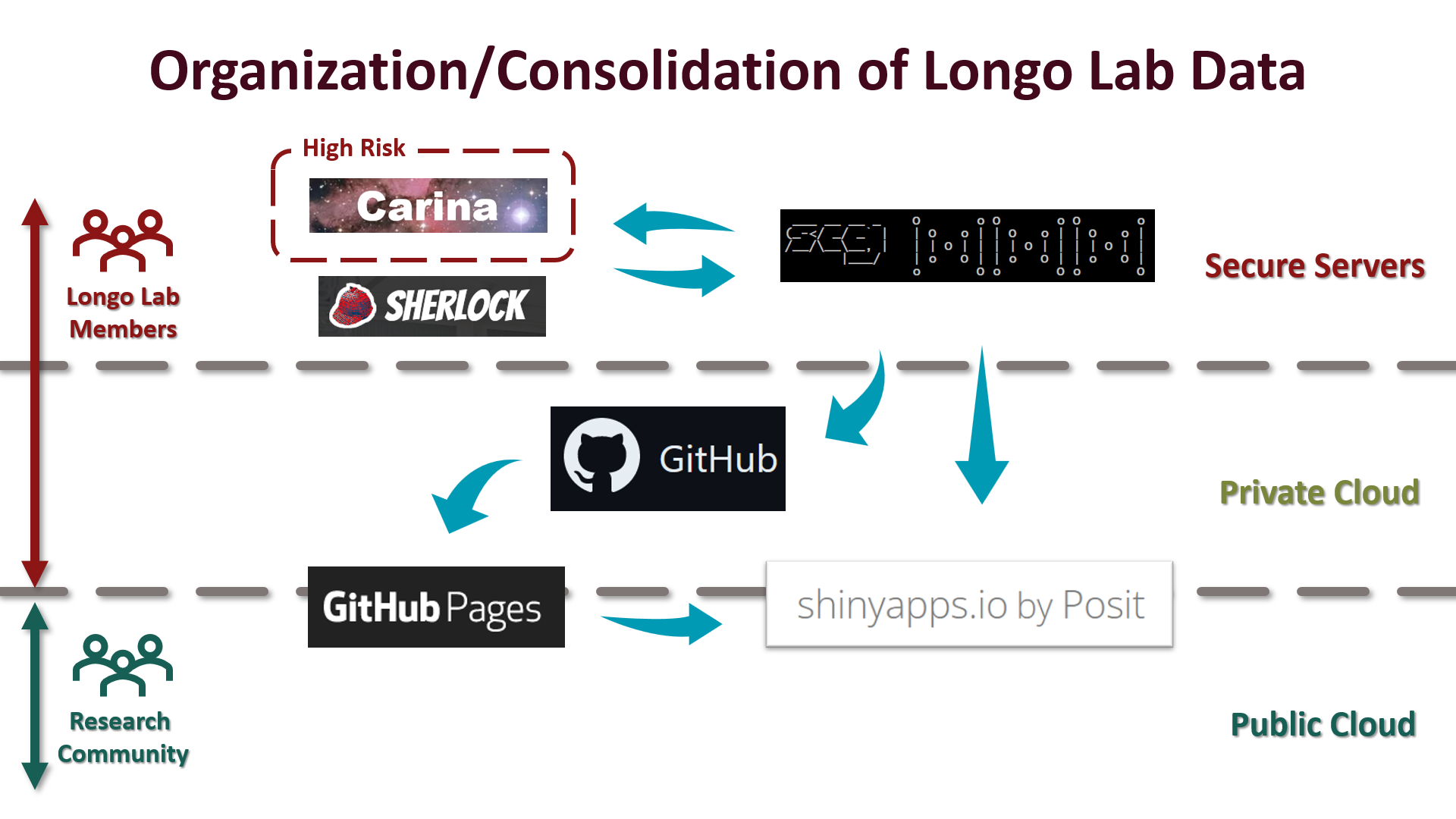
General Data Organization
For the purposes of general organization, it is good to think about what components exist in a research project. This is not the phase based components of project management, but the actual tangibles that can be grouped into four categories:
All of these elements are ideally maintained in resources that they are suited for. As a result, the full stack (above) is laid out with some forethough.
Data Storage
While not all datasets can be immediately transferred to Stanford’s Oak Storage, any that can be should be on there. For our lab, primary access to Oak is through our SCG account. If you are a lab member this is where you can backup your data, organized into projects. Your working machine should be set up with the University’s CrashPlan setup. Importantly if you are going to be using High Risk data in your project, both your computer and the server need to be configured appropriately, and we will design a specific data plan (i.e. not on Oak/SCG).
Ultimately, all raw data will be deposited in the appropriate repository during publication, and code for generating data will be backed up and made available as described below. Importantly, this all happens through SCG, so…put your project on SCG.
Project naming
The easiest way to track data is by
model_compound_experimentnomenclature. Use ALL CAPS for the mouse model and compound and make sure to always use underscores_instead of spaces. When creating a new project folder, be sure to check first if you are unsure, because it is much harder to change that project folder name than anything else about the project.
As you can see in the projects section, a certain amount of information is automatically connected between SCG and our other management tools. In order to keep projects straight, it is essential to know where your project goes and what it is called. Every SCG user has a $HOME folder. If you are demo-ing something, that is where you can try things out. The Longo Lab itself has a Lab folder, and in here, all data should be organized by project.
Data Processing
Stanford provides high end computing clusters SGC and Sherlock for this purpose, and while computing on your laptop is sometimes appropriate, it is encouraged to use the clusters whenever possible to (1) Facilitate the proper storage of your data, (2) facilitate managing and sharing your data with your collaborators and (3) not waste your time.
While cluster computing can be intimidating, SCG has made efforts to make this simpler with OnDemand graphical versions of common analytical software. Software that is associated with certain machines may not work in a cluster, but even in that case it is recommended to process the data on that machine and then transfer results to SCG.
Code maintenance via GitHub
A very important reason to keep your analysis on SCG in addition your data is that all coding scripts are backed up to our Github organization page nightly. You are welcome to do your own github commits as you work to save a full history of your code, and if your are particularly willing, you can enforce version control too (for more on this, see the style guide section).
Project Management
One of the biggest challenges of lab work is maintaining organization! Even computational analyses can take months/years to fully implement, so taking on multiple projects side by side becomes essential. You also have multiple people coordinating with one another on a shared resource (using GitHub). It is important to document your progress, if not to keep track, then to show evidence of all of your hard work. Just like a lab notebook at the bench, you need a digital notebook.
Project organization via GitHub
If you didn’t know, GitHub also has projects…
It ends up being quite useful to manage projects in GitHub as you both fill your notebook, but also get some experience with kanban-style agile frameworks:
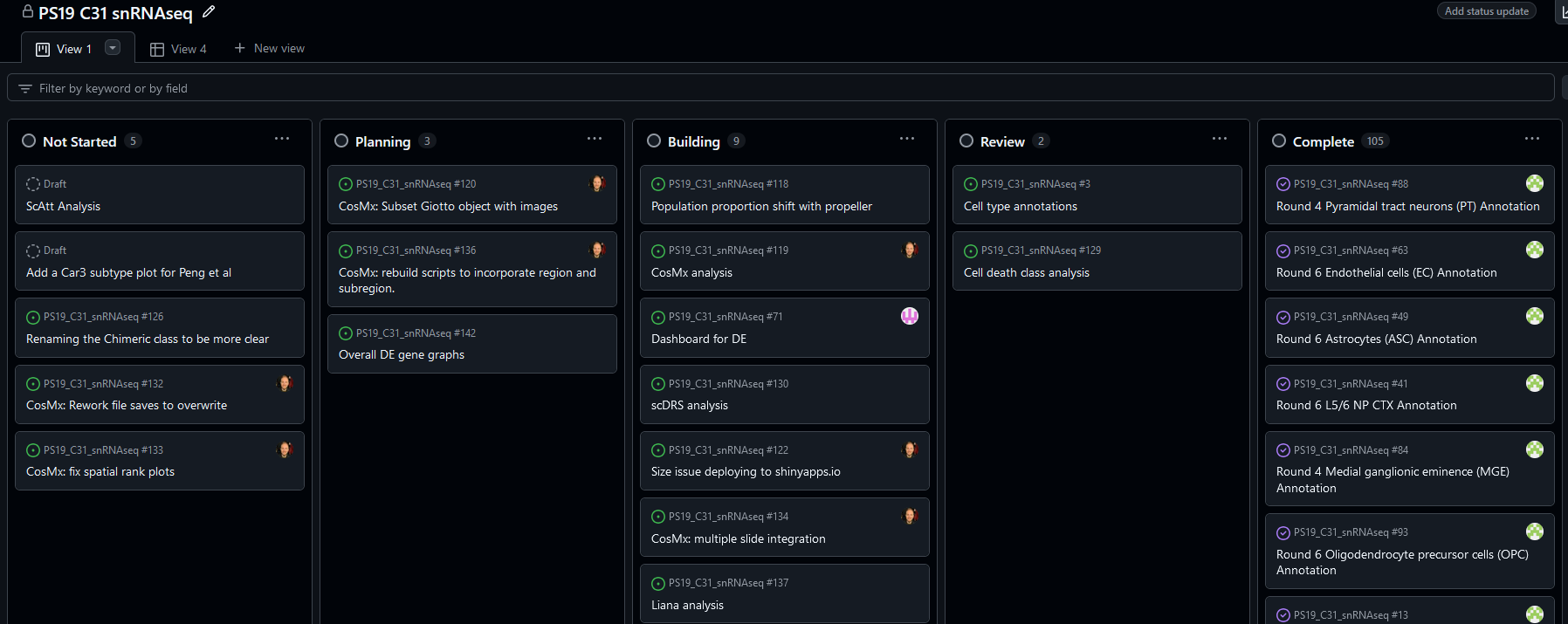
This allows for very precise notebooks where each project issue can have images & text. You can use markdown syntax and create tables as needed to communicate why you did what you did. Your properly documented code in the repository side evinces how you did it.
Setting up a project
Given the complexity of working with the cluster, ask for help setting up your project so it syncs properly with its repository.
Project Communication
The final pieces of your project are talking about it and publishing it (which is really still just talking about it).
Communication during
Stanford gives you a lot of options here, as does GitHub, with the latter being a much more permanent way to document something as notes. The Longo Lab does have a Slack workspace that is very useful for “Hey where are you?” type messages. #general is not used too often, it is more for announcements. #general_the_second is good for chats, lab happy hours, etc. Feel free to create your own #project_specific_channel to be able to check in. Lastly, some people need emails, so you can email the longo_labs list serv any time you want to share something more general like a paper.
Communication for publication
One of the often short shrifted components of any paper is code documentation & availability. Journals now strongly encourage it but I have yet to encounter a journal that actually enforces that in a meaningful way. Often at top tier journals papers will still have a link to a GitHub page with nothing but pseudocode for maybe 10% of the analysis.
Dashboards and code availability for your project
All of those private project repos can be flipped to public when your paper comes out. Making it really easy to auto generate your paper’s “code availablity” section
But not you, you have been documenting things in GitHub Projects, and your code is backed up from SCG to the repository, so at the time of publication we can simply make that information public. That’s it, in a few minutes most of your documentation is done. Keep in mind though that turning your project public means your commentary in the issues will now be public, so remember to keep it professional and constructive.
Dashboards
Beyond evidence of work, you can do one better and create some engaging dashboards to show anyone something useful, even on your phone! We have a few prebuilt dashboard templates to use for the most common type of work we do. They are implemented in Shiny apps.
Dashboard tutorials
Head on over to the tutorials section for some details or check them out in a public facing project.